Implementation Details
Next: Empirical Results
Up: AIDA*
Previous: Phase 3: Asynchronous
While the above description gives a general outline of the AIDA* scheme,
the actual implementation is more sophisticated:
- When a processor is done with its local nodes, it can start a new
iteration when it receives an out_of_work message or detects
a work_request with a higher cost threshold on the ring.
- To keep communication costs low, up to five nodes are bundled in a work packet.
To avoid the donator from giving away all of its non processed nodes, only
half of these are transferred.
- At the end of each iteration
the nodes in
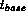 are re-ordered
are re-ordered :
Medium size subtrees with
:
Medium size subtrees with 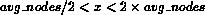 are sorted to the end of the array,
so that only work packets of average size will be transferred to other
processors.
are sorted to the end of the array,
so that only work packets of average size will be transferred to other
processors.
- In the hard problems (with many iterations),
the size of work packets can differ by an order of magnitude.
We therefore experimented with node splitting and node contraction
strategies [Chakrabrti et al., 1989] to adjust the work packets to an average size.
Our preliminary results indicate that
the additional overhead does not pay off.
Volker Schnecke
Mon Dec 19 17:27:56 MET 1994