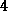 ).
).
Die Parallelisierung des Batch-Learnings besteht darin,
die Trainingsmenge aufzuteilen.
Die Gewichtsänderungen werden lokal pro Trainingsset berechnet,
anschließend werden die Gewichtsdifferenzen aufsummiert
und zu den tatsächlichen Gewichten hinzuaddiert.
Der Vorgang des Updatens findet einmal nach jeder Epoche statt (vgl. Abb. ).

Figure 3: Paralleles Batch-Learning