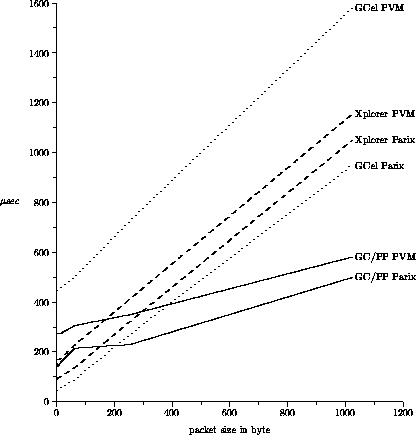
Figure 5: Communication speed between neighbored nodes
In a separate experiment, we benchmarked latency times and communication throughput of Parix and PVM on the GCel, GC/PP and PowerXplorer. Figure 5 shows the communication performance between neighbored processors for each of the systems. The PVM times include complete packing and unpacking on both sides, sender and the receiver.
The most apparent fact is, that in contrast to the other performance graphs, the GC/PP curves are not straight. This is attributed to the fixed initial overhead required for multiplexing the message among the four links of the communication subsystem. The multiplexing is done by four dedicated T805 communication processors. In practice, the computing performance would greatly benefit by latency hiding techniques, which is not reflected in these performance graphs. Hence, these graphs represent the worst case.
For the systems with PowerPC 601 processors (GC/PP and PowerXplorer), the communication throughput of PVM and Parix are very similar. Only for the GCel, there is a larger discrepancy between Parix and PVM communication performance, illustrated by the dotted line. This is caused by the GCel transputer nodes, which are by a factor of 20 slower than the PowerPC nodes. Hence, it takes much longer on the GCel to initiate a communication (function calls, data copying, etc.). Once the initial setup is done, the same throughput is achieved on the GCel as on a PowerXplorer. Due to the fat communication mesh, consisting of 4 links in each direction, the GC/PP communication is faster.