Zur Bestimmung der geeigneten Konfiguration des MLP-Netzwerks
wurden zahlreiche Experimente unternommen.
Folgende Parameter wurden variiert:
Wir verwenden in der Eingangsschicht der Netze die Zeitreihen von 53 Artikeln. Die Topologie wird beschrieben durch (#Eingangsneuronen:#Verdeckte Neuronen:#Ausgangsneuronen). Entsprechend der Anwendung für die Absatzprognose im Supermarkt werden zur Bestimmung der Prognosegüte die gegebenen Daten aufgeteilt: Als Trainingsmenge werden die Daten der Wochen 36/1994 bis 24/1995 verwendet. Um die Generalisierungsfähigkeit des Netzes überprüfen zu können, verwenden wir die 25. Woche 1995 als Testmenge. Damit ergeben sich 39 Trainingspaare für n=2 bzw. 38 für n=3 sowie jeweils ein nicht trainiertes Paar als Testmenge.
Durch zahlreiche Experimente haben sich eine Lernrate von 0.25 und ein Momentumterm von Null als gute Parameterwahl herausgestellt. Beim Vergleich der betrachteten Netztopologien zeigten sich die größeren Netze überlegen: Die Generalisierungsfähigkeit mit einem Sechstel der Anzahl der Eingangsneuronen in der verdeckten Schicht erweist sich hier als besser.
Bild 3 stellt den Fehlerverlauf mit dieser Parametereinstellung während des Trainings von 1000 Epochen für den in Bild 1 gezeigten Artikel dar. Aufgetragen sind die Fehlerverläufe für Trainings- und Testmenge für zwei Netze mit n=2 bzw. n=3. Es zeigt sich, daß beide Netze den Fehler auf der Trainingsmenge schnell reduzieren, während auf der Testmenge das Netz mit zwei Wochen Vergangenheit den kleineren Prognosefehler liefert.
Eine konkrete Prognose für die 25. Woche 1995 mit dem Netz 424:70:1 kann in Bild 1 als gepunktete Line abgelesen werden: Der Prognosefehler ist kleiner als ein Stück.
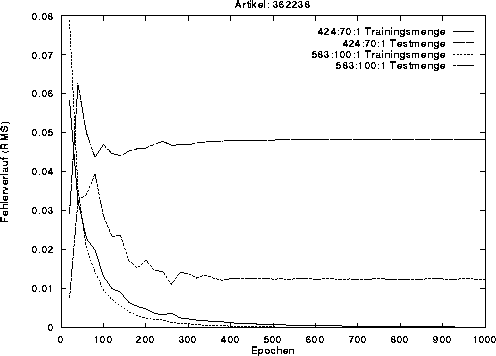
Figure: root mean square error während des Trainings

Table 1: Trainingszeiten unterschiedlicher Netze auf einer SPARC 20-50MHz
Im Vergleich zu früheren Prognosen zeigen die aktuellen Ergebnisse eine Verbesserung der Prognosequalität begründet durch die längere Historie seit September 1994. Die Rechenzeit zum Training der Netze ist Tabelle 1 zu entnehmen.