Zur Verringerung der Trainingszeiten des Backpropagation-Algorithmus ist dieser auf verschiedene Arten parallelisiert worden. Neben einer Parallelisierung des Batch-Learning, bei der die Trainingsmenge verteilt trainiert wird und die Gewichts- und Schwellwertkorrekturen nach jeder Epoche unter den Prozessoren ausgetauscht werden, sind zwei Parallelisierungen des Online-Trainings durchgeführt worden. Hierbei wird schichtweise im MLP-Netzwerk die Zuständigkeit für die Neuronen unter den Prozessoren verteilt, so daß die Matrix-Vektor-Operationen parallel durchgeführt werden können. Die eine Variante nach Morgan et.al. [5] verwendet einen kommunikationsintensiven Algorithmus, während die Parallelisierung nach Yoon et.al. [6] den Kommunikationsaufwand zu Lasten von Speicher- und Rechenbedarf reduziert.
Die parallelen Algorithmen sind mit Hilfe der Message Passing Systeme PARIX und PVM auf PARSYTEC Parallelrechnern implementiert worden. Bild 4 stellt für die Implementation auf einem PARSYTEC GC mit PowerPC Prozessoren die zeitliche Beschleunigung des Trainings durch die Parallelisierung (Speedup) dar. Dabei zeigt sich die gute Parallelisierbarkeit des Batch-Learning. Bei der Parallelisierung des Online-Trainings ist der Ansatz von Yoon dem von Morgan leicht überlegen, bei großen Prozessorzahlen skalieren beide Parallelisierungen wegen des hohen Kommunikationsaufwands nicht mehr.
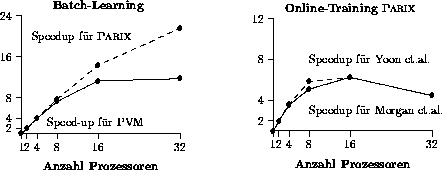
Figure: Speedups für PARSYTEC GC mit PowerPC Prozessoren